FastDDC and GPGPU: progress toward a full HF web receiver for everyone
While developing OpenWebRX, I always wanted to make it available to hams who have various hardware, instead of supporting a specific board that you have to buy in order to use the software. The idea of a full HF receiver is very good, and I imagined if anyone could have one, not just those who buy a specific board of a specific manufacturer.
The GPL protects you from company to improve your software and sell it for money without distributing the source code. It does not protect you, however, from someone who forks your software (which means making an own version incompatible with the original), then uses it as an essential part of his open source hardware project, puts the whole thing up to Kickstarter (which was impossible without your work), and goes away with your opportunities (and at least gives back the source changes that you have to port manually). In life it happens that a retired Silicon Valley engineer, who just moved to New Zealand, does this to a young guy, who has just written his thesis at the university - just because he can do it, as the license allows it.
I am very grateful to life, however, as I’ve already got very much from OpenWebRX: I was able to speak at conferences, and got a lot of positive feedback. Thanks everyone! Whatever happens to forks of OpenWebRX, I am still committed to writing more open source.
If you like OpenWebRX, you can support my open source work.
Now, back to the things that count: while there are already SDR boards that can supply a high bandwidth input signal (e.g. HackRF, bladeRF, etc.) the problem with making an SDR software that can receive the whole shortwave at once is the required computational power. For example, sampling 30 MHz bandwidth with a 16-bit ADC at 60 Msps means 120 MByte of data to process per second. In addition, as we are talking about a multi user SDR software here, the amount of computation gets multiplied by the number of clients.
Currently, OpenWebRX works well with sampling rates around 2.4 Msps, but 60 Msps is a bit more than this: it cannot be easily processed with a general purpose CPU, so we need to get into high performance computing (HPC), and use GPU or FPGA for parallel computations.
The performance bottleneck is the so-called Digital Downconverter (DDC), the signal processing block that selects a given narrow-band channel from the input, and also decreases the sampling rate. I’ve detailed the related algorithms in my thesis, and have also been speaking about having improved them with ARM NEON at TAPR DCC 2015.
FastDDC
To achieve even more speedup, I’ve decided to take the approach of this paper (by Mark Borgerding of 3dB Labs). I’ve called my implementation FastDDC, although this algorithm is a variation of fast convolution. It applies the frequency translation, anti-aliasing filter and decimation after taking the signal into the frequency domain. At the end, it translates the decimated signal back to the time domain.
To overcome the limitations of the algorithm described in the paper, I had to extend it by applying second frequency translation and decimation. You can view the block diagram of the algorithm below:
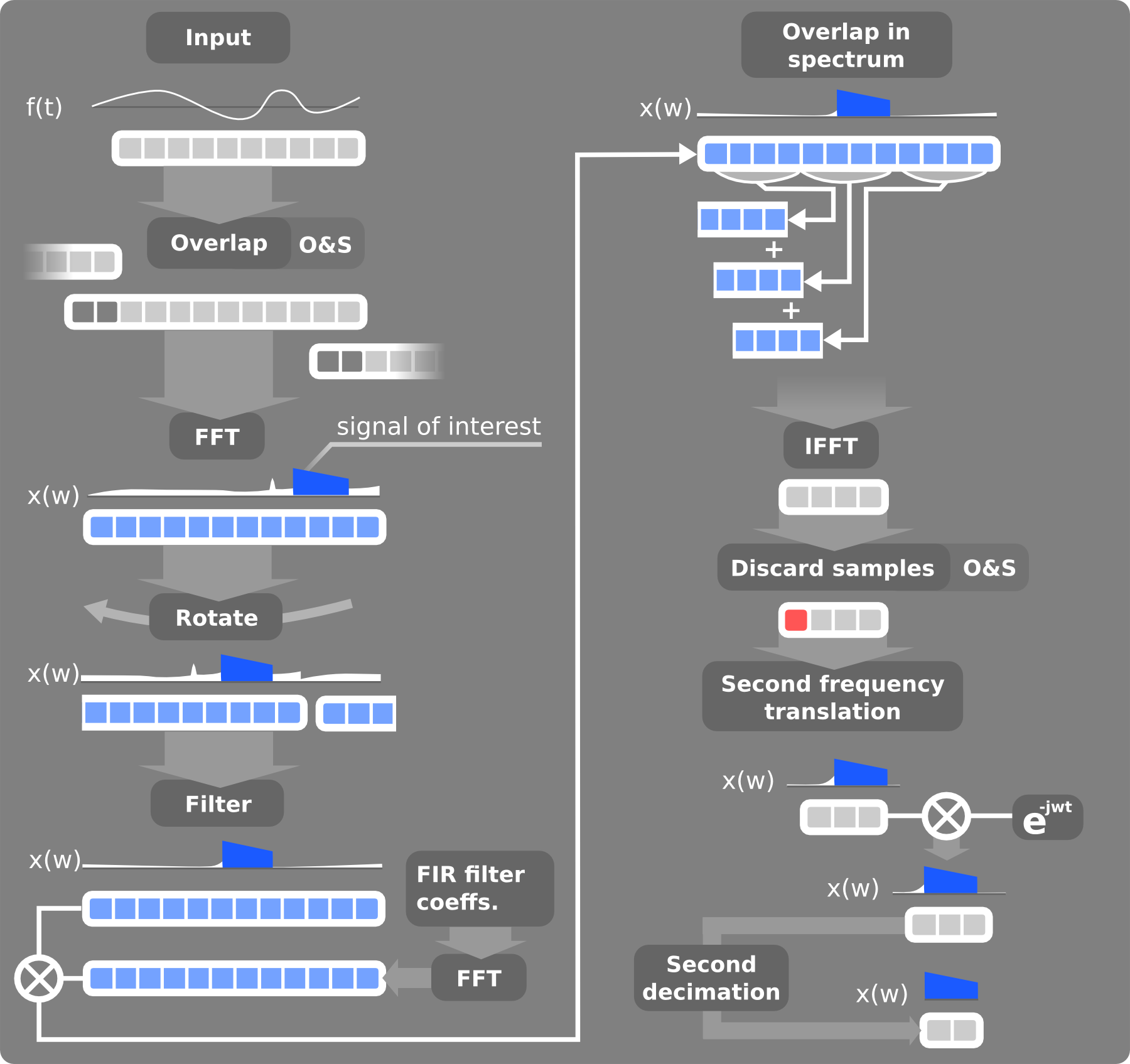
The FastDDC executes faster because the forward FFT has to be calculated only once for all channels.
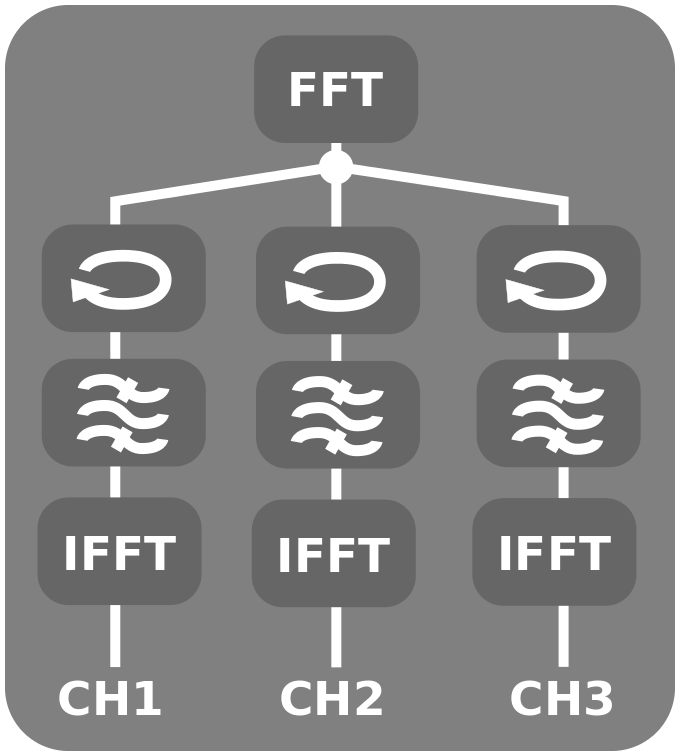
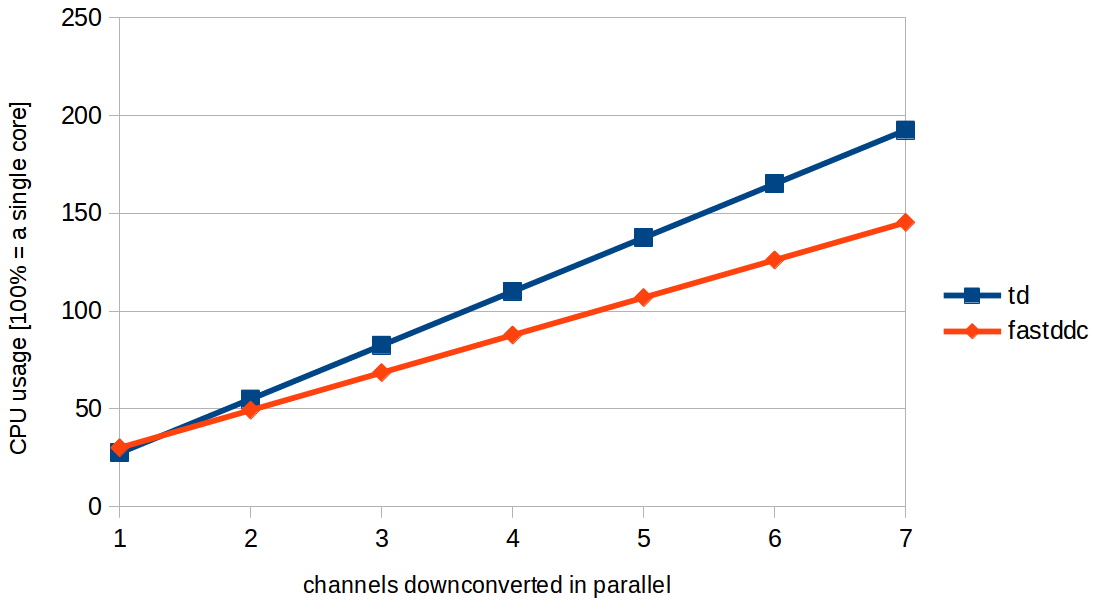
This means that the FastDDC can introduce performance gain if there are more than one channels. See a comparison between the old and the new algorithm on the graph below:
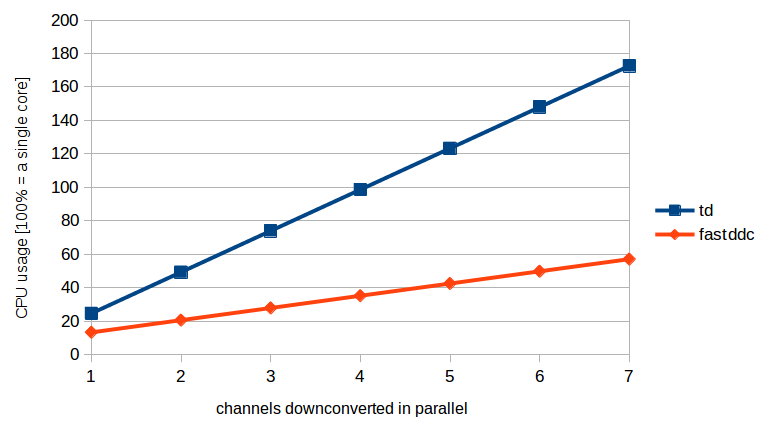
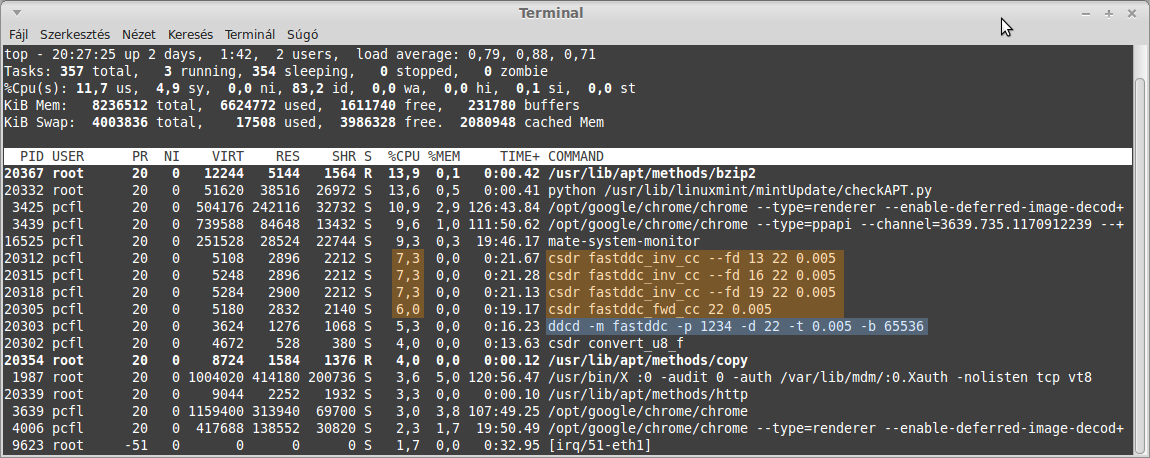
The graph has been taken with parameters of decimation = 22 and transition_bw = 0.005. Also take a look at the top command, while downconverting 3 channels in parallel. This is what happened with the old algorithms:
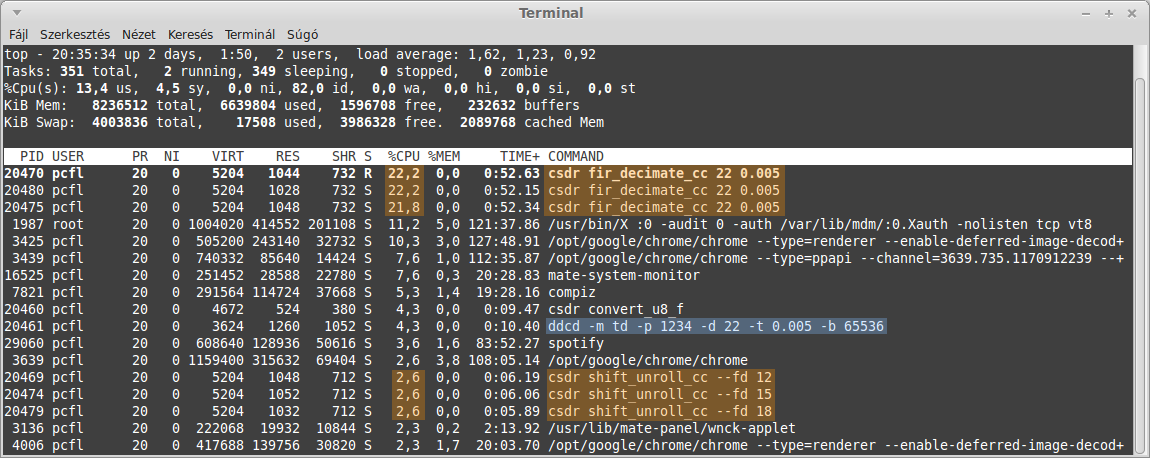
…and now with FastDDC:
Still, there are parameter combinations for which FastDDC cannot do that good:
In this case we used decimation = 185 and transition_bw = 0.000810791015625.
To summarize, FastDDC can gain an improvement of up to 300% in some cases. As an algorithm that runs on the CPU, it is able to speed up calculations to allow increased sampling rates even on single board ARM computers like the Raspberry Pi 2. The FastDDC is ready, but additional work has to be carried out to integrate it into OpenWebRX. Still, in itself it is not sufficient for channelizing the complete shortwave to multiple clients.
OpenWebRX and CUDA
In order to get additional improvement in speed, I’ve implemented the DDC for the GPU as well. For simplicity, the algorithm that has been parallelized is the traditional downconverter (not the FastDDC yet). The test program shows the following output on my system:
Generating input...done.
Testing GPGPU algorithms against their original, CPU-based versions.
Processing SHIFT on CPU...
Processing SHIFT on GPU...
Processing FIR_DECIMATE on CPU...
Processing FIR_DECIMATE on GPU...
======= SHIFT output: =======
#0 CPU: 0.527863 GPU: 0.527863 d: 0
#1 CPU: 0.40921 GPU: 0.40921 d: 0
#2 CPU: -0.288527 GPU: -0.288527 d: -2.98023e-008
#3 CPU: 0.228454 GPU: 0.228454 d: 0
#4 CPU: -1.05341 GPU: -1.05341 d: 0
#5 CPU: -0.282072 GPU: -0.282072 d: -1.19209e-007
(...)
======= FIR_DECIMATE output: =======
#0 CPU: 0.02478 GPU: 0.0248242 d: -4.42769e-005
#1 CPU: -0.389318 GPU: -0.389326 d: 7.77841e-006
#2 CPU: -0.348468 GPU: -0.348467 d: -2.98023e-007
#3 CPU: -0.0305233 GPU: -0.0305679 d: 4.45526e-005
#4 CPU: -0.338424 GPU: -0.338384 d: -3.99053e-005
#5 CPU: -0.182581 GPU: -0.182592 d: 1.09226e-005
(...)
Starting time measurement tests.
Processing 30 blocks of 131072 samples.
Processing SHIFT on CPU...
Elapsed time: 111.817449 ms
Processing SHIFT on GPU...
Elapsed time: 5.900833 ms
Processing FIR_DECIMATE on CPU...
Elapsed time: 2122.850518 ms
Processing FIR_DECIMATE on GPU...
Elapsed time: 113.473717 ms
Ready.
In conculsion, even with a laptop GPU (NVIDIA Quadro 1000M) about 17x speedup can be achieved. This algorithm still needs to be integrated into OpenWebRX.
I carried out this work to fulfil the requirements of Project Laboratory 2 and Heterogeneous Computing Systems subjects at Budapest University of Technogy and Economics.
Note: this article has last been edited on 2016-03-20.